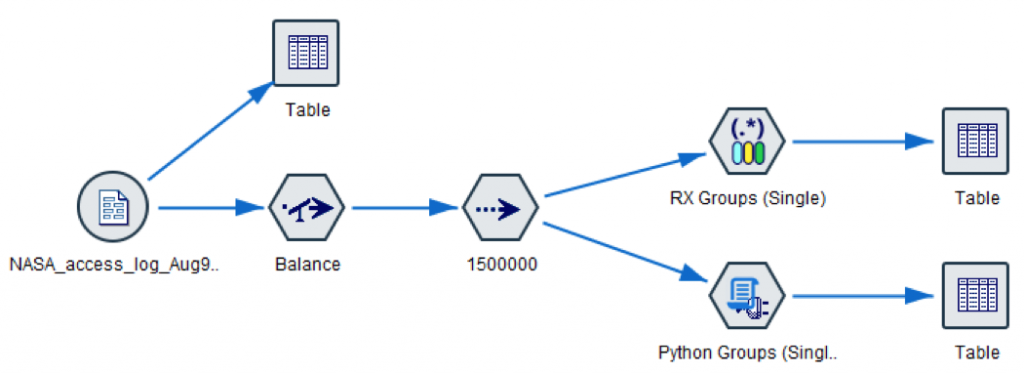
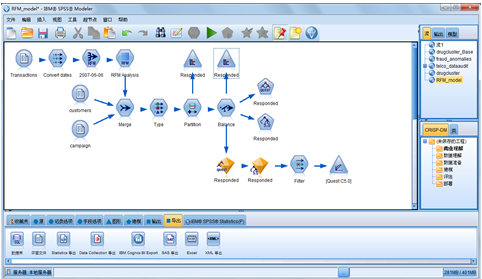
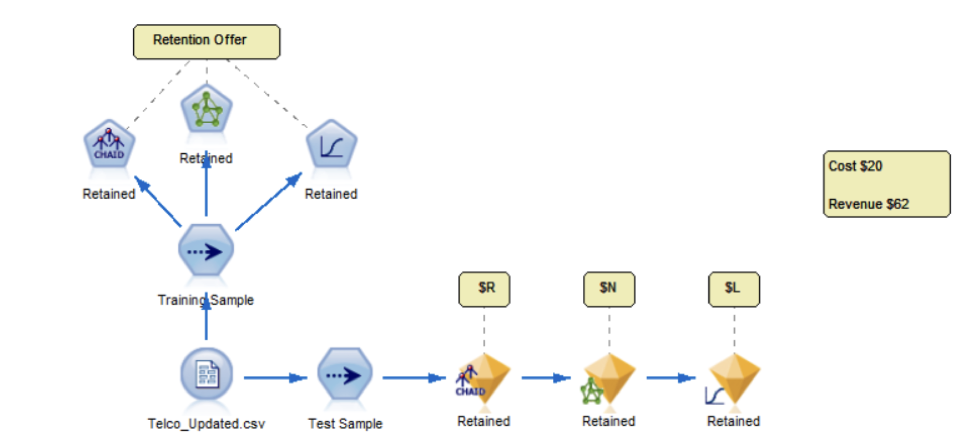
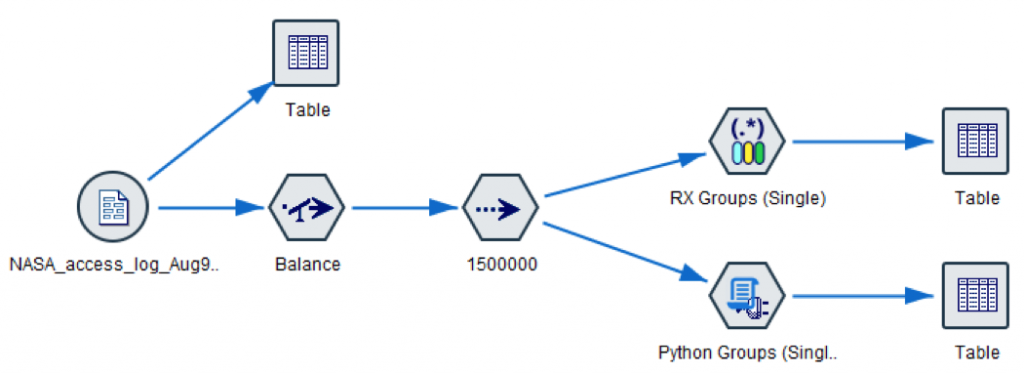
A-Z of analytics with IBM SPSS Modeler
IBM SPSS is one of the most versatile analytics tools available on the market today. In this A-Z guide we outline just some of the many features that make it great.
A-Z of analytics with IBM SPSS Modeler Read More »